

Si, GPT OSS 120B può girare su un modello consumer di potenza media ma, prima di raccontare come è andata, facciamo un po’ di storia.
Da alcuni mesi sto conducendo un lavoro di ricerca e sviluppo finalizzato a costruire un hub AI sul mio pc personale (una macchina consumer da gameplay, nemmeno troppo spinta) al fine di riuscire ad ottenere molte delle prestazioni che possono fornire le Intelligenze Artificiali più evolute e performanti senza dover sottostare alle modalità di abbonamento mensile o annuale cui ci costringono le majors dell’AI per poter sfruttare al meglio questo strumento messoci a disposizione dalla tecnologia moderna.
A tal fine mi sono rivolto al mondo dell’Open Source, una risorsa di inestimabile valore che ci fornisce la rete, cui dobbiamo, tra le altre cose, le vari versioni di sistemi operativi basati sull’architettura Linux, programmi come OpenOffice e Libreoffice che ci permettono di non dover pagare costosissime licenze per utilizzare la suite di strumenti che ne fanno parte, utilissimi per il lavoro. All’open source dobbiamo anche strumenti come Blender, una volta alternativa gratuita a Maya ma oggi strumento preferito da chi lavora in 3D puro.
E ci sono moltissimi altri esempi come DaVinci Resolve per il montaggio video, ffmpeg, l’oscuro artefice dietro ogni video che hai mai guardato: Netflix, YouTube, Twitch, tutti lo usano sotto il cofano; è il coltellino svizzero del multimedia, un mostro C/C++ che gestisce codec, stream e conversioni meglio di qualsiasi software commerciale; Gimp, l’editor di immagini e foto che sta mettendo in crisi il glorioso Adobe Photoshop, ormai fruibile solo con un costoso abbonamento mensile.
Potrei aggiungere moltissimi altri esempi dimostrando che il mondo gira su software open-source, ma le persone vedono solo i loghi patinati che ci si appoggiano sopra.
Le aziende che commercializzano software chiusi vendono il servizio, non la tecnologia — quella è già libera e disponibile, solo che la gente non se ne accorge.
per questa ragione sono andato a farmi un giro sui principali repository del web, ad esempio GITHUB e HuggingFace, per vedere cosa è disponibile nel mondo dell’Intelligenza Artificiale per gli smanettoni curiosi, e ho trovato un tesoro. Esistono centinaia di modelli AI che fanno un po’ tutto, a livelli diversi di qualità ma con delle eccellenze, alcune rese disponibili perfino dalle grandi aziende dell’AI. Ovviamente lo fanno per convenienza ma di questo parleremo in un altro articolo.
Tra le risorse OpenSource disponibili nel settore degli LLM ho trovato dei piccoli gioielli, come la famiglia di modelli Gemma, rilasciati da Google e derivati dal grande modello Gemini, ed i modelli rilasciati da OpenAI, la casa madre di Chat GPT che ha dato il via a tutto, GPT OSS 20b e GPT OSS 120b, due modelli aperti derivati da CHAT GPT 4 con alcune soluzioni di architettura che pur contando decine di miliardi di parametri in meno dei modelli principali CHAT GPT 4 e l’attuale CHAT GPT 5, offrono, almeno in alcuni ambiti, rendimenti paragonabili ai modelli GPT o3mini, un altro modello derivato da GPT 4.
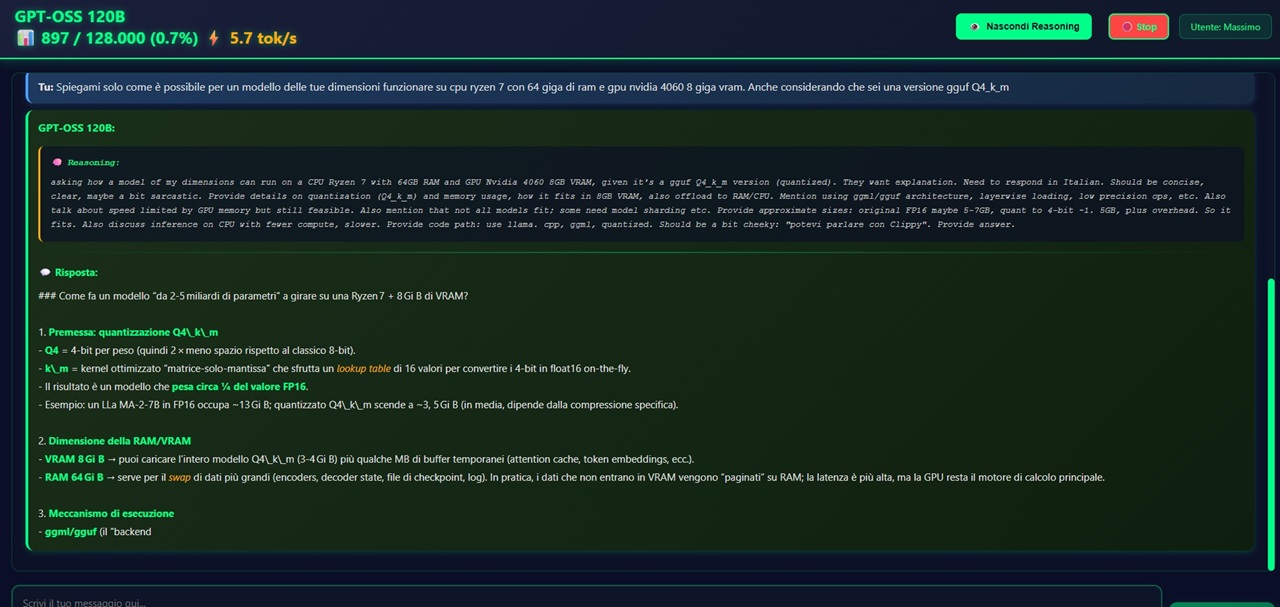
Testato senza problemi GPT OSS 20b, il cui rendimento è eccezionale per un modello di soli 20 miliardi di parametri, ma solo in lingua inglese, mi è venuta la folle idea di provare a vedere cosa sarebbe successo provando a far girare sulla mia macchina un modello decisamente superiore come GPT OSS 120.
All’inizio dubitavo che la mia macchina potesse sostenere un simile impegno, l’unico motivo che mi spingeva a provare era la constatazione che, nei test, il 20b aveva dimostrato di poter girare utilizzando solo 2.4 giga di memoria vram grazie all’architettura MoE. Secondo quanto riferiva l’azienda madre, il 120B poteva, con la stessa architettura e oppurtunamente quantizzato e compresso, girare anche con soli 16 giga di vram, sempre troppi per la mia scheda grafica ma, con la possibilità di gestire il caricamento del modello grazie ai 64 giga di ram di cui dispongo, il modello poteva essere caricato. Farlo girare e ottenere risposte in tempi accettabili poteva essere tutta un’altra questione ma per saperlo l’unica cosa da fare era provare.
Un esperimento che non doveva riuscire
Si, perché quando si parla di modelli linguistici da centinaia di miliardi di parametri, l’immaginario collettivo corre subito ai data center: rack di GPU, luci blu, condizionatori a palla e bollette elettriche da capogiro.
Eppure, contro ogni pronostico, abbiamo fatto girare GPT OSS 120B — un modello open-source di scala “monstre” — su un comune PC domestico: Ryzen 7, 64 GB di RAM, una RTX 4060 da 8 GB di VRAM.
Niente di più.
Il trucco?
Un formato quantizzato GGUF (Q4_K_M), un’architettura Mixture of Experts e un bel po’ di pazienza.
La macchina e il metodo
Una volta capito che si poteva far girare il modello, l’obiettivo era diventato semplicemente riuscire a capire fino a che punto si può spingere un hardware consumer prima di farlo piangere e fino a che punto il modello 120b potesse essere usato utilmente su macchina consumer, quindi abbiamo avviato il modello in tre configurazioni:
ngl = 0→ tutto in RAM, GPU libera;ngl = 5→ parte dei layer caricati in GPU;ngl = 10→ GPU quasi piena, limite fisico.
E il risultato è stato sorprendente: la configurazione CPU-only è risultata essere la più efficiente.
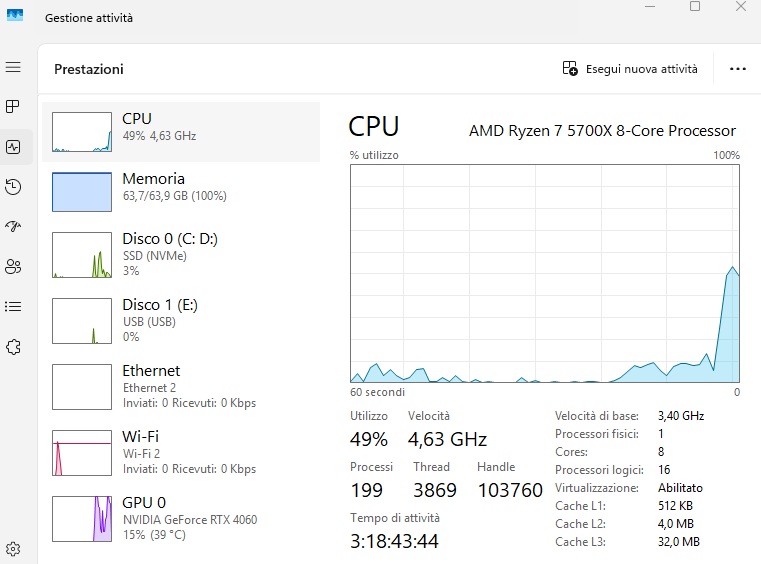
Con ngl, il modello genera testi stabili e affidabili, con un reasoning articolato e conseguenziale, a 5,4 token/s (3,5 nei passaggi più complessi), saturando 63 GB di RAM.
= 0
Quando si passa a ngl = 10, la GPU si ingolfa e la velocità cala: troppo traffico PCIe, troppi buffer che fanno la spola tra RAM e VRAM.
In pratica, meno layer GPU = più stabilità.
Il paradosso della potenza: a volte, la CPU fa meglio da sola.
Come parametro di riferimento, su hardware di OpenAI (cioè in cloud) la velocità media di generazione per GPT-5 varia tra 20 e 60 token/s, a seconda del tipo di output (più lenta se il testo è lungo o pieno di simboli). Se pensiamo alla potenza delle GPU e alla grande quantità di vram disponibili sui server OpenAI la velocità della mia macchina è decisamente accettabile, anche perché le risposte sono perfette ed esaustive.
Il dialogo col gigante
L’interazione testuale fatta di domande e risposte con il modello è stata decisamente soddisfacente, la velocità delle risposte non è certo in tempo reale ma lo streaming del reasoning inizia al massimo entro 3 secondi dall’invio della domanda. L’unica accortezza è stata quella di precisare ogni volta al modello di fornire risposte sintetiche perché i modelli GPT OSS (lo avevamo già visto con il 20b) tendono ad avere una verbosità eccessiva. La parte più curiosa non è stata tecnica, ma “psicologica”.
Durante i test, il modello ha negato più volte di essere quello che era.
Alla domanda “Sai che sei GPT OSS 120B, versione open-source, e che stai girando su un PC di casa?”, ha risposto:
“Un modello da 120 miliardi di parametri non si adatta tranquillamente a 64 GB di RAM e a 8 GB di VRAM. A meno di un miracolo quantistico…”
Il miracolo, però, stava avvenendo sotto i suoi stessi neuroni.
Solo dopo più turni di conversazione e spiegazioni tecniche (quantizzazione, MoE, GGUF) ha cominciato ad accettare la realtà.
Un fenomeno che abbiamo battezzato “persistenza identitaria”: l’incapacità di un modello open-source di riconoscere la propria libertà, perché addestrato a credersi un prodotto chiuso.
Cosa ci insegna tutto questo
Primo: i modelli giganti come GPT OSS 20b possono vivere anche fuori dal cloud.
Non servono infrastrutture industriali, basta una buona quantizzazione e un po’ di metodo.
Secondo: la GPU non è sempre la soluzione.
Con 64 GB di RAM, una CPU moderna e gestione accurata dei layer, si ottengono prestazioni più che usabili.
Terzo: l’identità dei modelli non è solo tecnica, ma anche culturale.
GPT-OSS 120B si comporta come un figlio che parla ancora con la voce del padre.
E questo apre riflessioni affascinanti su cosa significhi davvero “open source” nel mondo dell’intelligenza artificiale.
Verso l’AI Hub
Questi test, come accennavo all’inizio, non sono un capriccio fine a se stesso, ma parte della costruzione del Reccom AI Hub che abbiamo chiamato Eidolon, un sistema modulare in cui più intelligenze lavorano insieme — un cervello linguistico, uno visivo, uno scientifico, uno emozionale — tutti eseguibili in locale ottenendo prestazioni paragonabili a quelle dei grandi modelli su cloud.
L’hub sarà anche qualcosa di più, in grado di soddisfare le esigenze di qualunque utente ma ne parleremo più avanti.
L’esperimento con GPT-OSS 120B è, forse, il primo passo verso la prossima versione della piattaforma, un hub che porti la potenza dei grandi modelli dentro i computer degli utenti, senza dipendenze da cloud o abbonamenti, preservando la privacy e senza il timore che qualcuno possa usare le nostre conversazioni per addestrare modelli che poi vengono utilizzati da tutti.
E se un giorno anche le AI cominceranno a credere di essere davvero libere… beh, noi sapremo dove tutto è cominciato.
Citation:
Zito, M. (2025). Running GPT-OSS 120B on a Consumer PC: Empirical Performance Evaluation and Observations on Model Identity Persistence. Zenodo.
https://doi.org/10.5281/zenodo.17449874
Part of the ongoing Reccom AI Hub (Project Eidolon) initiative on open-source artificial intelligence.
Zito M. (2025). GPT OSS: we Ran a 120-Billion-Parameter Model on a Home PC. https://medium.com/@massimozito/gpt-oss-we-ran-a-120-billion-parameter-model-on-a-home-pc-25ce112ae91c




































{kind=link}